La inteligencia artificial en cualquiera de sus modalidades como por ejemplo ChatGPT están revolucionando la industria digital. Ahora, la búsqueda de información es mucho más sencilla e intuitiva. Sin embargo, el aspecto fundamental para que las herramientas de IA como ChatGPT puedan aportar información fiable a los usuarios son los datos y conocimientos utilizados para el aprendizaje de dichas herramientas de inteligencia artificial. Las herramientas de inteligencia artificial utilizan bots conocidos como crawler (Rastreadores Web) que escanean las paginas Webs de internet para obtener la información correcta y de calidad que a posteriori su herramienta ofrecerá a sus usuarios.

Tabla de Contenidos
Relacionado: Como detectar contenido generado por Inteligencia Artificial | ChatGPT
En pocas palabras podemos afirmar que para que las herramientas de Inteligencia artificial como ChatGPT funcionen correctamente, necesitan de la información de paginas Webs ya creadas y accesibles en internet. Este método de aprendizaje es lo que precisamente muchos creadores de contenido describen como robo de información y competencia desleal.
Ningún creador de contenido en sitios Webs desea que su trabajo sea robado y usado por herramientas que se lucran por mostrar este contenido a otros usuarios. Recordemos que ChatGPT cobra suscripciones a sus usuarios por la realización de consultas. Las respuestas de ChatGPT a estas consultas puede utilizar información obtenida de tu sitio Web. Además, por si fuera poco, las herramientas de Inteligencia artificial no se destacan por ofrecer referencias en forma de enlaces, a los contenidos que han sido utilizados para proporcionar su respuesta.
Tal y como hemos comentado anteriormente, ChatGPT de OpenAI al igual que otras herramientas de IA, utilizan rastreadores para obtener la información de los sitios web de forma similar a como lo hacen los motores de búsqueda. Sin embargo, existe una gran diferencia en la finalidad y uso que a posteriori se hace de la información de tu sitio Web.
Cómo funciona el rastreo de OpenAI (y otros rastreadores de IA) respecto al de los motores de búsqueda
Un rastreador web (también conocido como araña o robot de motor de búsqueda) es una especie de bot automatizado que escanea Internet en busca de información. Esta información escaneada se almacena de una manera que se mucho más fácil de acceder para su motor de búsqueda.
Los rastreadores web indexan el contenido de cada URL relevante, dando prioridad a sitios Webs con buena reputación y relevantes para una consulta de búsqueda específica. De esta forma si por ejemplo, un usuario realiza una búsqueda de un término como “error bluetooth al conectar auriculares al iPhone”, el motor de búsqueda ofrecerá como resultado, los sitios Webs que mejor solución ofrecen a dicha consulta.
Automáticamente, esto significa que el propietario de la Web que ofrece una solución al problema se beneficia directamente ya que podrá monetizar su contenido ya que el usuario que realiza la consulta debe acceder a la Web para obtener los detalles de la solución.
El motor de búsqueda puede ofrecer las URLs más relevante al usuario que realiza la búsqueda, gracias a que con anterioridad, un rastreador a escaneado y extraído la información de cada página de cada sitio Web.
Por otro lado, al aceptar el rastreador web de OpenAI llamado GPTBot (al igual que otros rastreadores de herramientas de IA), permitimos acceso a GPTBot a nuestro sitio web y por consiguiente permiso también a entrenar el modelo de IA para que sea más fiables y preciso, e incluso pueda ayudar a expandir las capacidades del modelo de IA.
En este caso el propietario del sitio Web que posee contenido de valor y relevante para una búsqueda especifica puede estar contribuyendo a las respuestas que ofrecen herramientas como ChatGPT pero sin beneficio para ellos. Pero esto no es todo, ya que en el caso de que la IA acabe reemplazando por completo a los motores de búsqueda, los propietarios de sitios Webs pueden que hayan contribuido de forma directa en la herramienta que ha acabado con su modelo de negocio.
Todo esto puede llevar a los propietarios de sitios Webs, decidir NO dar acceso a los rastreadores de herramientas de IA como GPTBot, CCBot o ChatGPT-User.
Nota Importante: Asumimos que como propietarios de un sitio Web, conoces que cualquier sitio Web tiene la capacidad de permitir o bloquear rastreadores Webs ya sean de motores de búsqueda como de herramientas de Inteligencia Artificial a través del archivo robots.txt
Dicho esto, a continuación, os mostramos detalladamente como bloquear los rastreadores de ChatGPT, GPTbot y CCBot, para que las herramientas de inteligencia NO puedan acceder y usar tu contenido Web:
Como bloquear completamente el acceso de GPTBot a tu sitio web
1. Descarga el archivo robots.txt de tu sitio Web.
2. Abre el archivo .txt con un editor de texto como por ejemplo el bloc de Notas
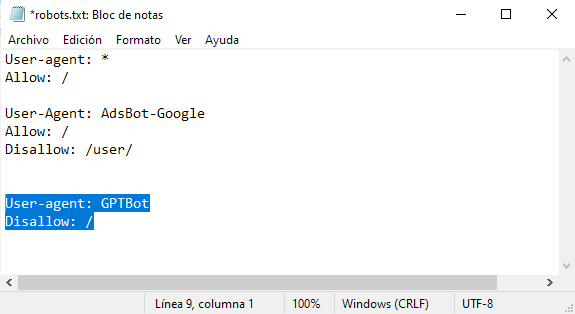
3. Al final del texto que tengas escrito en el archivo robots.txt deberás añadir lo siguiente:
User-agent: GPTBot
Disallow: /
4. Guarde el archivo .txt y súbelo de nuevo al directorio raíz de tu hosting para que el crawler de ChatGPT no pueda acceder al contenido de tu página Web.
Como bloquear GPTBot para que no pueda acceder URLs específica de tu sitio Web.
1. Descarga el archivo robots.txt del directorio raíz de tu hosting.
2. Abre el archivo con un editor compatible.
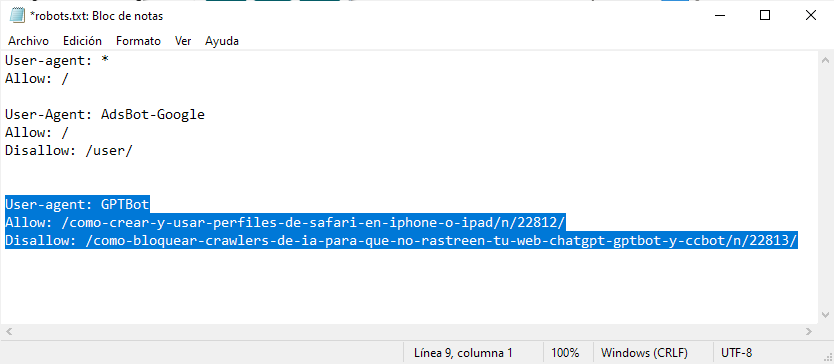
3. Añade lo siguiente, justo debajo del texto que el archivo ya contiene:
User-agent: GPTBot
Allow: /URL-sin-el-dominio-1/
Disallow: /URL-sin-el-dominio-2/
Nota Importante: Las URLs añadidas junto a “Allow” si podrán ser rastreadas por el crawler de ChatGPT. En “Disallow”, deberás añadir las URLs que NO quieres que sean rastreadas.
Como bloquear Common Crawl (CCBot) en tu sitio Web y que no roben tu contenido para entrenar IA
* Common Crawl (CCBot) es el rastreador responsable del 80% del entrenamiento de herramientas de Inteligencia Artificial por lo que bloquear este crawler tiene todo el sentido.
1. Sigue los pasos 1 y 2 de los métodos anteriores.
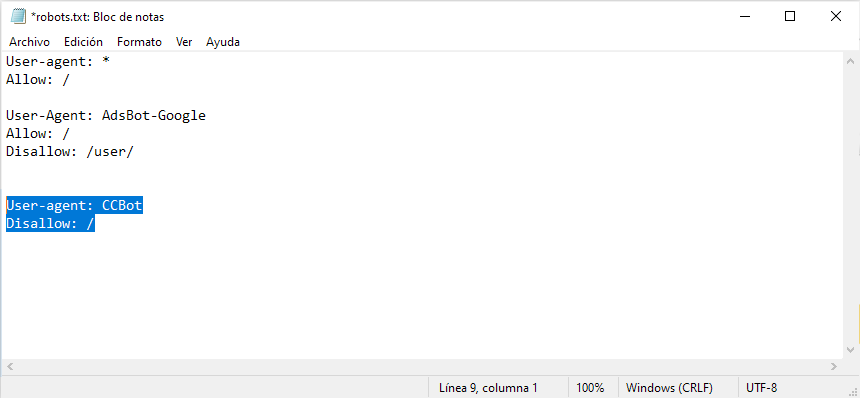
2. Ahora introduce el siguiente texto justo debajo de texto ya presente:
User-agent: CCBot
Disallow: /
3. Guarda los cambios en el archivo .txt y renglón seguido, súbelos a tu hosting.
Como bloquear nuevos complementos de ChatGPT de tu sitio Web.
1. Sigue los pasos 1 y 2 de los métodos anteriores.
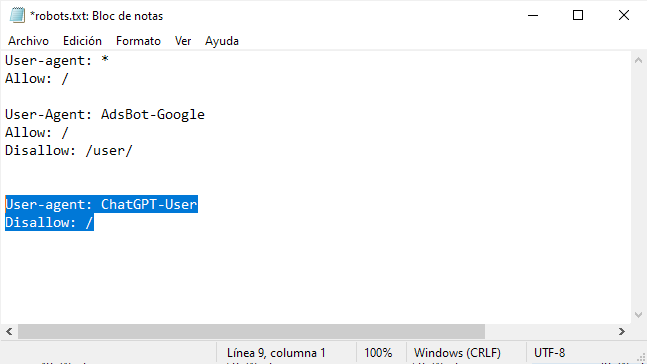
2. Renglón seguido tendrás que copiar y pegar el siguiente texto en el archivo robots.txt:
User-agent: ChatGPT-User
Disallow: /
3. Guarda el archive y súbelo a tu hosting.
Nota Importante: Cabe destacar que este tutorial es una solución para que las herramientas de inteligencia artificial NO puedan rastrear el contenido de tu Web y No puedan usar este contenido para entrenar sus herramientas. Sin embargo, no podremos evitar el uso de información ya obtenida mediante este rastreo que se haya realizado antes de los cambios realizados en el archivo robots.txt.