Las siglas OCR provienen de Optical Character Recognition. En español,(ROC) Reconocimiento Optico de caracteres. Esto está dirigido a la digitalización de textos, al identificar a partir de una imagen de manera automática caracteres o símbolos pertenecientes a un alfabeto, para luego guardarlos en forma de datos, para más tarde poder manipularlos a través de un programa de edición de texto o alguno parecido.

Este tipo de software o servicio puede ser de gran ayuda para aquellos usuarios que viajan al extranjero y tienen que lidiar con diferentes letreros o carteles que necesita traducir pero que puede ser muy complicado escribir en su ordenador o Smartphone para su posterior traducción. Otros usuarios que también pueden estar interesado son los usuarios que suelen manejar archivos PDF que no permiten su modificación o copiado del texto para poder editarlo como desee incluso en otros software ofimáticos.
De esta manera solo con captar una foto de texto o cualquier imagen que contenga texto, podremos transformarlo o convertirlo en texto totalmente edítamele y manejable. Este software o servicio podemos encontrarlos de diferentes tipos: Software de escritorio, páginas Web o servicios ofimáticos Web.
La mayoría de dichos servicios o software son gratuitos. Si quieres conocer una lista de ellos, presta atención a la siguiente:
Google Drive (Suite ofimática Online)
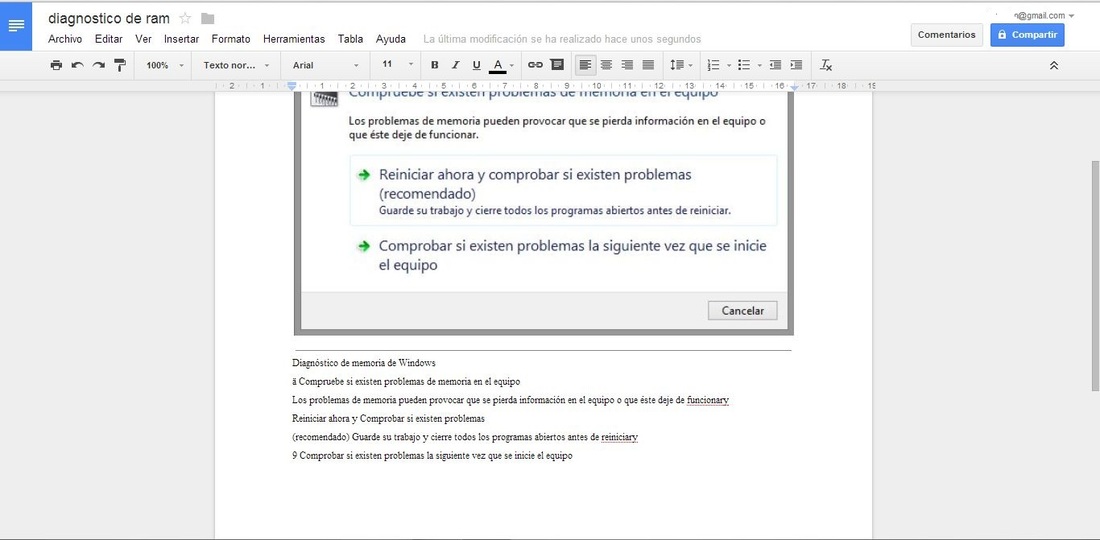
Google Drive a través de su editor de texto Google Docs puede realizar la captación de texto captada en una imagen para proceder posteriormente a su edición en dicho editor de texto.
- Lo primero que deberemos hacer será acceder a Google Drive desde nuestro ordenador para lo cual necesitarás una cuenta Google o de Gmail.
- Una vez que nos encontremos en la interfaz de Google Drive, deberemos subir el archivo de imagen del cual queremos captar el texto.
- Una vez subido el archivo, deberemos hace clic derecho sobre él y seleccionar la opción de "Abrir con... Google Docs".
- Cuando Google Docs se abra, aparecerá en él la imagen seleccionada y justo debajo de ella, se verá cualquier texto que aparezca en la imagen abierta. Ahora se podrá usar el texto como desee.
El resultado es bastante bueno, reconociendo formato básico como negritas y cursivas.
FreeOCR.net Download (Software)
FreeOCR es gratis y lo que hace es reconocer el texto a partir de imágenes y PDF. El programa es capaz de trabajar con archivos importados del escáner o con documentos ya creados, por lo que el trabajo con el documento es inmediato. Tiene un soporte lingüístico de 11 idiomas, entre ellos el castellano.
La interfaz es fácil de utilizar ya que es bastante parecida a la barra de herramientas de Microsoft office en su versión más reciente. Se tiene acceso a través de los iconos a las funciones del programa.
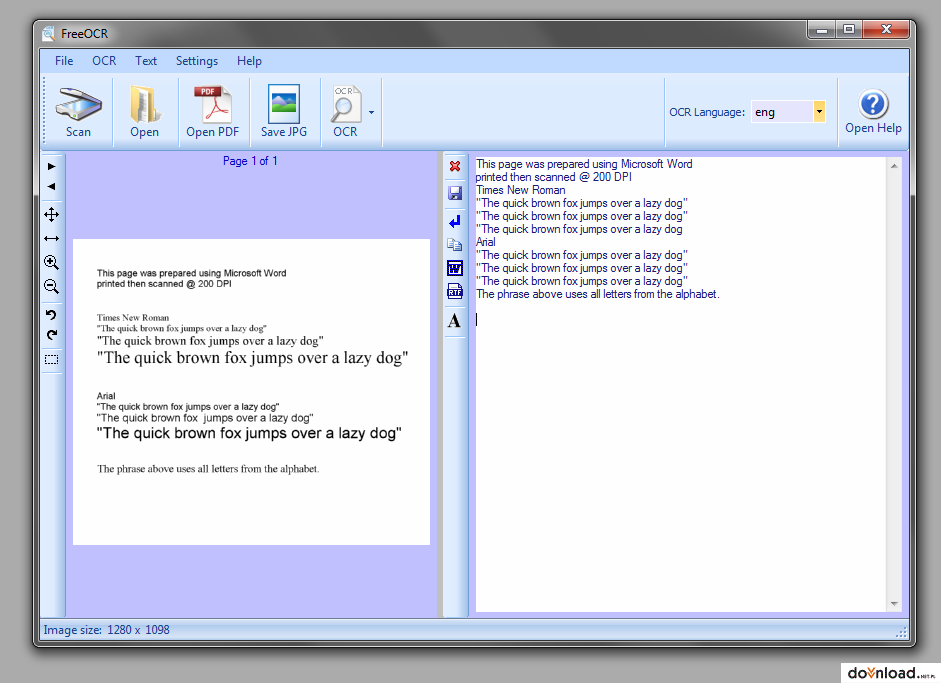
OCR se consigue por dos vías: utilizando un archivo de texto realizado por ti, o bien por el escaneado de un archivo a través de FreeeOCR. Utilice la poción deseada en la barra de herramientas. Si usted opta por explorar el contenido, el programa le sugerirá que seleccione un dispositivo para buscar y adecuar las opciones básicas, como pueden ser el color (blanco/negro, color, escala de gris) y el tamaño del documento.
Si ya contará con un documento PDF o una imagen en la memoria, solamente debe de abrir el archivo y leer siguiendo en orden la ejecución del programa. Los formatos de imágenes mas populares son soportados fácilmente por FreeOCR.
La ejecución de OCR es veloz. En la ventana de la derecha se situará en forma de texto el archivo reconocido, lo cual le facilita la realización de operaciones secundarias –guardar o editar en formato RTF oDOC. Es posible elegir una fuente predeterminada que tenga almacenada.
ABBYY FineReader Professional Edition (Software)
ABBY FineReader Professional Edition es un programa para la conversión de OCR, PDF, imágenes escaneadas y fotografías digitales en un formato el cual podamos editar. El programa busca de forma precisa y segura la conservación de la distribución como en el documento original. LA ultima versión de FineReader nos ofrece la novedosa tecnología: Adaptive Document Recognition Technology (ADRT) la cual analiza el documento en su totalidad, sin tener que hacerlo pagina a pagina, siendo capaz de reproducir de una forma muy precisa un archivo editable y formatos capaces de hacer fluir el texto, como un diseño versátil y original, editar estilo y formato.
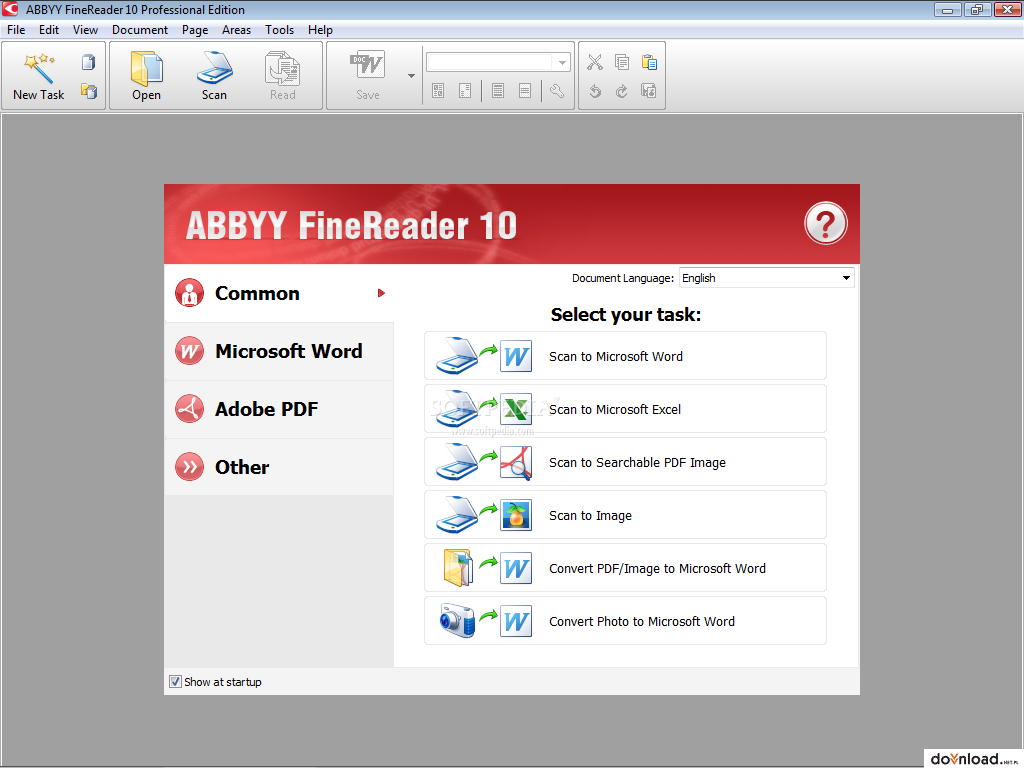
La cámara OCR ha sido renovada y ahora identifica de forma automática las imágenes de la cámara digital ajustando la distorsión para la obtención de buenos resultado en el OCR sin que cambiemos la configuración antes del cambio.LA interfaz está orientada a los resultados y la automatización QuickTasks para que la conversión resulte lo más rápida, precisa y fácil posible. El programa reconone hasta 179 idiomas.
Image To PDF OCR Converter. (Software)
La herramienta Image To PDF Converter convierte directamente los formatos TIFF, JPEG, TIF, BMP y otros cuantos de formatos de imagen en formatos PDF, lo que permite búsquedas. Con este programa realizara fácilmente archivos PDF, pudiendo convertir jpeg a pdf, png a pdf, GIF a PDF, TIFF a PDF, TIFF a PDF, BMP a PDF, EMF a PDF. Tiene compatibilidad con B/W y la imagen clara, para realizar PDF de gran calidad.
Free Online OCR (Página Web)
La tendencia actual y más recomendable es el uso de servicios web así no tendremos que descargar e instalar un software en nuestro ordenador.
El servicio web Free Online OCR nos deja subir un archivo PDF (o imagen) para obtener el texto directamente. El caso de este dominio, es quizás uno de los mas atractivos y deslumbrantes a los que podemos acudir.
La ejecución consta únicamente de dos pasos. Primero elección del archivo de nuestro disco.

Segundo seleccionar el formato en el cual vamos a dar salida al texto captado.
Entre los formatos de salida a nuestra elección están PDF,TXT,DOC y RTF. En algunos segundos podrás iniciar la descarga del resultado a tu ordenador.
El archivo que resulta no contiene la misma calidad que el hecho por Google Docs puesto que algunos párrafos pueden llegar a omitirse, aunque a cambio tiene que intenta generar un documento DOC manteniendo el formato originario, cosa que coogle Docs no cumple.
NewOCR (Página Web)
Otra alternativa más sobria y que incluye más publicidad sería, NewOCR el cual tiene mas fuentes y reconoce hasta 58 idiomas, amplia el número de opciones, formatos de entrada y salida. La desventaja: Solo extrae el texto sin formato.
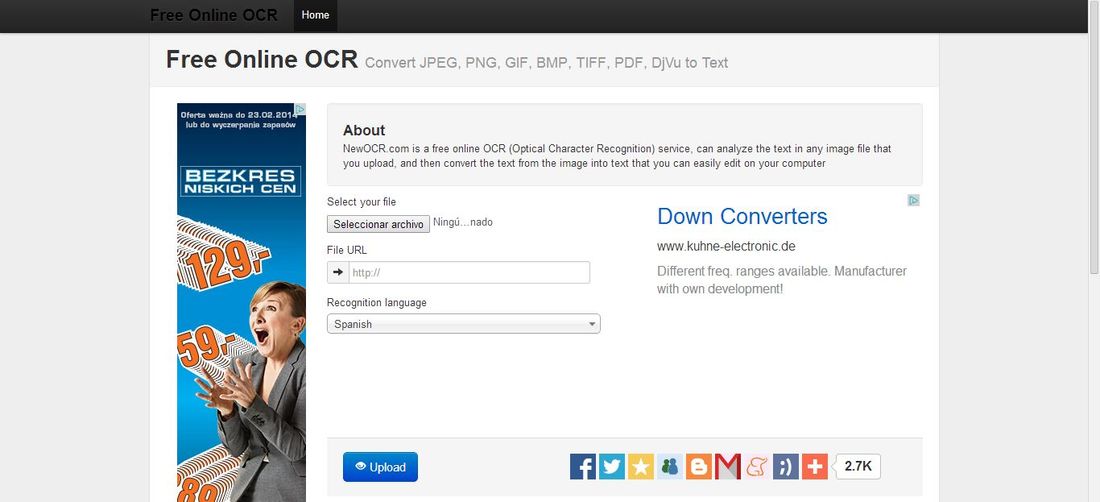
El funcionamiento es muy parecido al de otras web similares:
Hacerlo desde una URL o eligiendo un archivo desde tu ordenador.
Después eliges idioma, y pulsas el botón Upload.
NewOCR le mostrara la captación del texto en la parte de abajo, pero sin formato, por lo que será necesario copiarlo y pegarlo en un editor de texto que tengamos.
Online OCR (Página Web)
El proceso consta de dos pasos, subir la imagen y el reconocimiento se realiza después de la introducción de un CAPTCHA
Free Online OCR tiene en su web una versión de pago y otra gratuita. La diferencia entre las versiones radica en una serie de limitaciones que están en la versión gratuita. Estas limitaciones son que solo puedes convertir 15 imágenes/hora, tamaño máximo 4 Mb y no podras subir varias imágenes en un ZIP:
Pero posee una serie de ventajas como que no es necesaria su instalación. Reconocer caracteres y texto de los documentos escaneados en PDF (incluyendo documentos de paginas multiples), imágenes capturadas por cámaras digitales y fotografías. También tienes en la versión gratuita el reconocimiento de 32 idiomas.
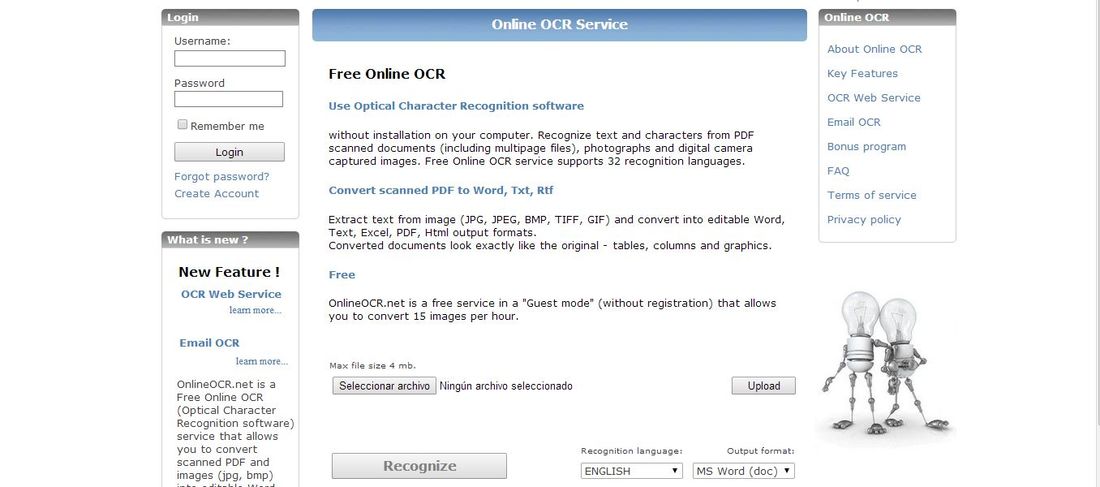
Convierte a texto imágenes de formatos (JPG, JPEG, BMP, TIFF, GIF)y los pasa a los formatos de salida Word, texto, Excel, PDF y HTLM
Los documentos tratados con el programa son idénticos al original incluyendo los graficos, columnas y tablas que puedan contener
Mas tarde el resultado se verá como texto plano, aunque se podrá descarga en el formato que eligieses: DOC, XLS o TXT.
Sorprende el resultado que se consigue, superando ampliamente a todos los anteriores. Reconode el texto prefectamente y lo presenta en un formato DOC respetando la maquetación inicial (aunque las imágenes aparecen en blanco y negro)
